
Seguramente muchos conoceréis Internet Archive, una organización sin ánimo de lucro fundada en 1996, que nos permite acceder a cualquier sitio web, –aunque lleve varios años offline–, gracias a las instantáneas del mismo que va creando a lo largo del tiempo, así como de diversas colecciones multimedia, juegos y millones de libros.
Una Biblioteca de Alejandría del siglo XXI con una base de datos gigantesca para salvaguardar el legado de internet –curiosamente almacenada en una antigua iglesia en San Francisco, es la imagen que abre el post– .
Obviamente no hace de backup, pero si nos permite averiguar cual ha sido la evolución de una página determinada y su aspecto en momentos puntuales, gracias a las capturas realizadas, incluso aunque ya haya desaparecido.
Para ello podemos acceder a la web del proyecto e ir consultando una por una las diferentes imágenes fijas de una URL, utilizando su servicio Wayback Machine.
waybackpack
La otra opción es utilizar aplicaciones como esta waybackpack que os traigo hoy, que nos descarga un archivo con todas las capturas tirando una simple linea de comandos y ahorrándonos mucho tiempo.
Instalando waybackpack
Antes que nada vamos con la instalación. Al ser una aplicación construida en Python, podemos instalar waybackpack en cualquier Linux con el gesto de paquetes pip (disponible en los repositorios de todas las distros), tal que así:
sudo pip install waybackpack
Ejecutando waybackpack
Su uso tampoco presenta mayores complicaciones:
waybackpack lamiradadelreplicante.com -d ~/Escritorio/test --start 2011 --end 201606
donde el parámetro -d marca la ruta de descargar al directorio que elijamos, start la fecha de inicio y end la fecha de la última instantánea a descargar (formato YYYYMMDDhhss) y la URL, bueno ahí ya podéis poner la que más rabia os de 🙂
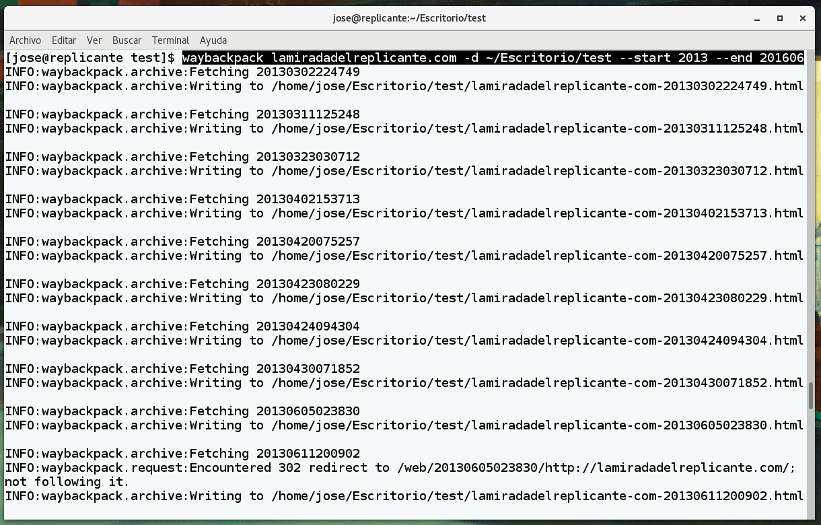
Para mayor comodidad podemos prescindir de la fecha de inicio:
waybackpack lamiradadelreplicante.com -d ~/Escritorio/test --end 20160601
Como resultado vamos a tener un puñado de archivos html descargados en el directorio seleccionado, que podemos abrirr con el navegador para su consulta.
Si en vez de descargarlos preferimos visualizar las diferentes URLs en la terminal podemos hacer algo así:
wayback lamiradadelreplicante.com –list
Tenéis más opciones de ejecución en la ayuda del programa:
waybackpack -h
y más información del proyecto en su página de GitHub.
Realmente interesante y llamativo ya que hasta un pequeño blog como el mio tiene varias capturas desde que comencé en el año 2007 en WordPress.com.
Pero es especialmente útil para blogs ya desaparecidos y buscar y descargar información sobre ellos.
Ehh! que tu blog no es «pequeño» llevas un montón de años dando guerra con Linux.
Y si! a mi también me gusta que quede ese recuerdo de web y sitios que ya no están online.
Gracias Replicante , no tenía ni idea de ese sitio , una mina de oro en información de todo tipo.
De nada Felipe! un placer
Excelente, Replicante. Conocía del sitio web, pero no la aplicación.
Gracias. 🙂
La verdad es que está muy bien. Es pasarse por github y encontrar siempre algo interesante.
Un saludo
Buenas Jose,
Hace tiempo que conozco el sitio, pero la aplicación no, así que genial 🙂
Para periodistas de investigación está genial la herramienta, para que muestren como algunas web’s de prensa escrita distorcionan en muchos casos las noticias!! (;
Para restaurar un sitio web desde el Archivo web archive.org puede probar este servicio – https://es.archivarix.com/